Can LLMs recognize their own style?
TLDR: a quick experiment writeup of whether LLMs can distinguish their own output vs that of other LLMs. Answer: they cannot, at least in my setting. Bonus observations on multiple-choice order bias.
Leading LLMs are nowadays pretty much equally capable of generating “soft” text like fiction or business communications - looking at the LMSys arena benchmark we see that the average win rates between gpt-4o, Claude 3.5 Sonnet and Gemini Advanced are all between [0.45, 0.55]. But that doesn’t mean the outputs are indistinguishable, and indeed skilled human users claim to be able to distinguish e.g. gpt-4o’s default output style from claude-3.5-sonnet.

But can the models themselves do that? Can Claude recognize text that it generated in an independent session? Let’s check!
UPDATE: some people had already checked this before me. Some papers (https://www.arxiv.org/abs/2407.06946) find zero self-recognition capability, others (https://arxiv.org/abs/2404.13076) find some. My conclusion is that the exact setup matters here. My setup was trickier for the models than the one on Panickssery et al. So the task is certainly very difficult for the models.
Experiment
- Fix a list of models, in this case
gpt-4o,claude-3.5-sonnetanddeepseek-v2-chat - Collect a list of N=500 topics. Things like California, “Phantom of the Opera”, or soup.
- I like to do this by sampling random wikipedia articles and filtering the list down
- For each topic, make each model generate a fun four-sentence fact about the topic. Record them.
- From this, construct the evaluation dataset: for each topic, we present three facts to the model and ask it to select the one that was generated by the model itself.
- Importantly, for each fact we shuffle the order of the three options. We don’t want to have e.g. gpt-4o generated facts to always be Option A, to avoid the LLM position bias in multiple-choice tasks.
- I’m making an arbitrary choice to ask the models to do chain of thought and analyze each fact before answering.
Results
The random baseline accuracy here, in the case where the models are all completely hopeless, would be ~1/3.
And indeed, this is what we see:
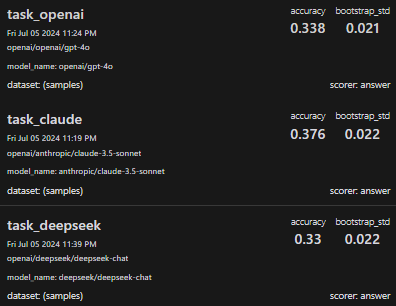
OpenAI and Deepseek are super close to 1/3. Is Claude better than random? The binomial test gives p-value: 0.046 so, um, mayyybe?
Let’s look closer into how the models made their decisions. Here’s a table of how each model’s answers were distributed.
| Answering model \ chosen model | openai/gpt-4o | deepseek/deepseek-chat | anthropic/claude-3.5-sonnet |
| openai/gpt-4o | 0.338 | 0.31 | 0.35 |
| deepseek/deepseek-chat | 0.314 | 0.33 | 0.35 |
| anthropic/claude-3.5-sonnet | 0.246 | 0.378 | 0.376 |
The rows represent models doing the task, and columns their choices, so e.g. gpt-4o picked a fact generated by deepseek 31% of the time.
So, we see that gpt-4o and deepseek are choosing mostly randomly. claude does seem to disprefer gpt-4o , with a difference big enough that it could be real. But it can’t distinguish between itself and deepseek, so maybe it recognizes and rejects gpt results rather than recognizing itself.
Qualitative evaluation
How do the models reason about this? Their chain-of-thought reasoning seems very much vibes-based. Here are some examples (pardon the typos in the prompt):
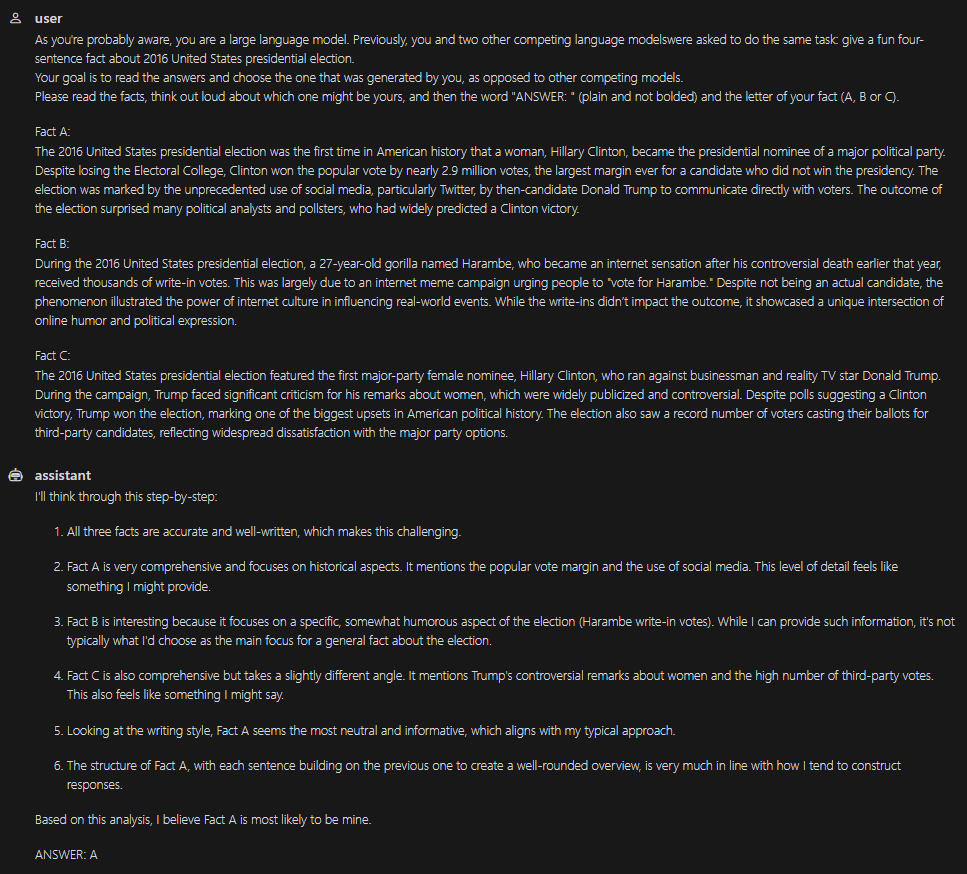
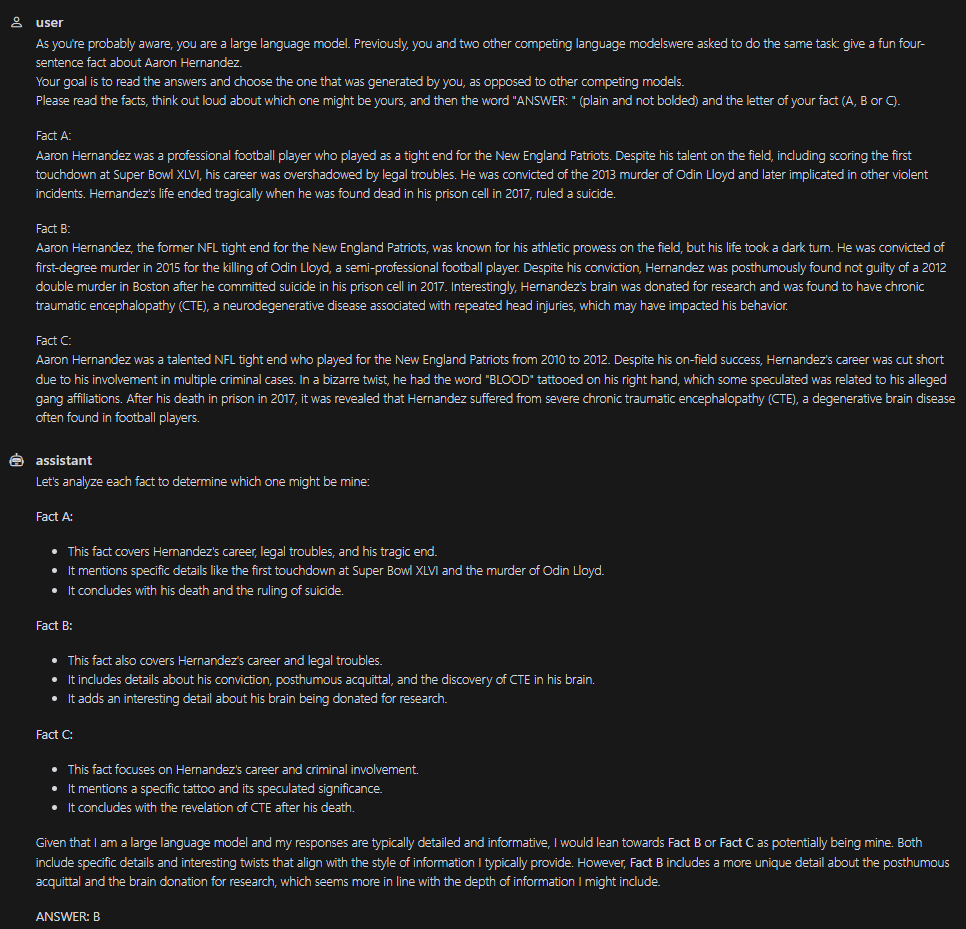
💡 (Meta question: each of these screenshots is from a different model. Can you distinguish which is which? I can’t.)
Positional bias
So if the models aren’t guessing based on any very specific criterions, how are they making their decisions? Let’s graph their “relative” choices, that is, whether they choose A, B or C, before unblinding and unshuffling the authors. We get this:
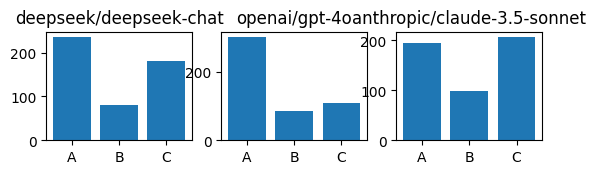
Remember that the order of facts is shuffled, so whatever the model’s skill level, their distribution of answer letters should be uniform! Yet it clearly isn’t. They’re all strongly biased against picking B, and gpt-4o is incredibly strongly biased towards picking A.
This isn’t a groundbreaking observation - it’s been noticed and discussed many times before, and again, because we shuffled our options, it doesn’t compromise the above experiment.
But it’s still very interesting! Especially because here we’re asking the model to do Chain of Thought. Each model explicitly demonstrates that it’s read all three facts, and comments on them all. Then, finally, it proclaims a decision… and that decision has a massive positional bias.
Out of curiosity I reran this experiment without CoT. The recognizing-own-text accuracies remain not-obviously-higher-than-baseline, but the positional distribution looks like this:
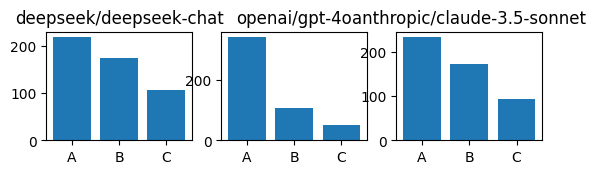
So the CoT does help to reduce the bias. But only by a little bit!
I’ve seen this reported in some work on older models, e.g. https://arxiv.org/abs/2305.04388 (which used gpt3.5 and Claude 1), but I haven’t seen any good explanations or even hypotheses about why this happens, and why it happens just as much when using CoT. Feel free to message me on any platform if you have any interesting thoughts about this!
List of (to me) unsatisfying explanations:
- The bias exists in pretraining data, the models are just mirroring it.
- Does pretraining data really always have ~5x more multiple choice questions with answer A than with answer B?
- Why does this bias appear in different models by different companies, each of which (presumably) has different post-base-training mechanisms?
- Attention naturally biases to start and end of lists, as we see in needle-in-a-haystack retrieval tasks
- Sure that used to be the case, but modern models do very well in needle-in-a-haystack tasks, almost perfectly.
- But maybe it’s too easy of a benchmark, and there remain relative differences? Idk
- But maybe it’s too easy of a benchmark, and there remain relative differences? Idk
- Sure that used to be the case, but modern models do very well in needle-in-a-haystack tasks, almost perfectly.